Coder intégralement en UTF8
Le codage des caractères n'est généralement pas le souci majeur de nombre de webmasters et développeurs. On reprend les morceaux de code trouvé ici ou là sans se préoccuper des conséquences de ce choix, jusqu'au jour où...
Le choix d'un bon encodage
Pour faire simple, chaque caractère qui s'affiche sur l'écran au travers d'un navigateur
correspond généralement à un code. C'est en tout cas vrai pour tous les chiffres et
caractères alphabétiques non accentués: 0..0, A..Z,
a..z et quelques caractères typographiques complémentaires: ?!$@...
Le premier réflexe, quand on est webmaster débutant, c'est de regarder le code des autres et de récupérer ce genre de codage HTML:
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
Ici, c'est l'encodage iso-8859-1 qui est sélectionné. En clair, si j'envoie
le mot été le navigateur est censé afficher la même chose.
Les mauvaises surprises commencent si on a édité son fichier source dans un environnement qui ne gère pas nativement cet encodage: MS-DOS ou Linux.
On risque de voir apparaître ceci: été.
Une des solutions, préconisées par le W3C, est de convertir les caractères accentués en entités HTML:
éenéàenà- ...etc.
Certains éditeurs HTML font ça automatiquement. Les entités HTML permettent d'utiliser des caractères non-latins dans des pages ne pouvant les affichant sous leur forme directe:
ΓpourΓζpourζ- ...etc.
Ainsi, le caractère € a comme entité €.
Il existe bien un encodage dans lequel on peut utiliser le caractère € sans avoir à recourir à son
entité:
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-15">
En encodage iso-8859-15, on peut utiliser tous les caractères accentués
français, et le caractère €, ainsi que certains caractères alphabétiques spéciaux sans
recourir à leurs entités HTML respectives.
Il est vrai que si vous êtes amenés à gérer des pages exclusivement en français, l'encodage ISO est suffisant. Mais vérifiez bien que vos fichiers sources sont également correctement encodés.
Par contre, si vous êtes amenés à utiliser des caractères exotiques, dans un site en plusieurs langues
par exemple, l'encodage que nous préconisons est UTF-8.
Pour ceux qui ne comprennent pas bien ce qu'est UTF8, voir la page wikipédia
suivante:
http://fr.wikipedia.org/wiki/UTF-8
Nos pages HTML en UTF-8
En premier lieu, on va déclarer la balise META selon la nouvelle syntaxe préconisée
par la norme HTML5:
<meta charset="UTF-8">
UTF-8 est l'encodage natif pour les systèmes UNIX/Linux. Il offre l'avantage de
gérer une large palette d'alphabets et symboles en complément du jeu ASCII (codes 0-127). Ainsi,
dans cette page HTML nous avons inséré des textes en russe, arabe, japonais et hébreu par simple copié-collé:
- Этот текст на русском языке
- هذا النص باللغة العربية
- このテキストは日本語です
- זהו טקסט בעברית
Voici le code source:
<ul> <li>Этот текст на русском языке</li> <li>هذا النص باللغة العربية</li> <li>このテキストは日本語です</li> <li>זהו טקסט בעברית</li> </ul>
Pour en revenir à notre alphabet français, l'encodage UTF-8 a quand même un léger
inconvénient: un caractère spécial é par exemple, occupera 2 octets au lieu
d'un octet en ISO-xxxx. Mais c'est toujours mieux que l'entité HTML é
qui occupe 8 octets!
Pour sauvegarder notre page HTML encodée en UTF-8 à partir de WordPad, cliquer sur Fichier et sélectionner Enregistrer sous:
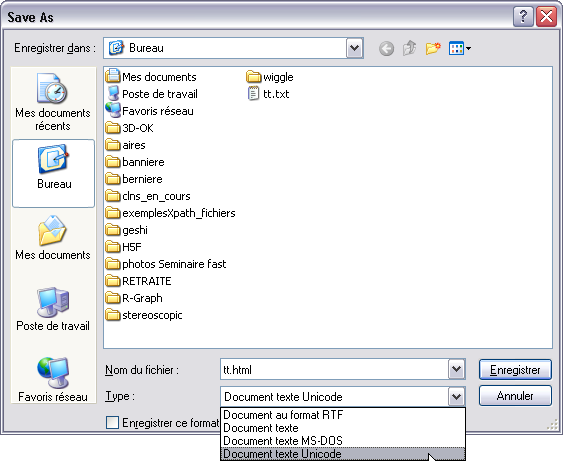
En bas de fenêtre, sélectionner Type et choisir Document texte Unicode.
Pour sauvegarder notre page HTML à partir de Gedit sous Linux, c'est encore plus simple:

si on fait Fichier puis enregistrer sous le format par défaut est automatiquement sélectionné en UTF-8.
Pour les environnements de développement dédiés, il existe des options et paramétrages permettant la sauvegarde des fichiers sources en UTF-8:
- PsPad se débrouille parfaitement avec l'encodage UTF-8. En haut de page, cliquer sur Format et sélectionner UTF-8.
- ZEND Studio n'affiche correctement les caractères d'un fichier en UTF8 que si le projet a été déclaré avec l'encodage UTF8,
- netBeans édite également les sources UTF8 avec la même contrainte que Zend Studio. Avantage pour Netbeans, on peut copier/coller des portions de code entre deux projets avec des encodages différents, les caractères accentués seront ré-encodés correctement dans le projet cible...
A titre d'exercice, pour tester le bon encodage d'une page HTML, voici un code source minimal:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>un jour en été</title> </head> <body> <p>Cet été je vais à la plage, ça vous dit de venir?</p> </body> </html>
Si vous avez bien suivi, copiez et collez ce code HTML dans WordPad (sous Windows) ou Gedit (sous Linux).
Enregistrez ce code dans un fichier test.html, puis une fois enregistrée, sélectionnez ce fichier avec bouton-droit de la souris et ouvrir avec le navigateur de votre choix.
Si vous voyez affiché ceci Cet été je vais à la plage, ça vous dit de venir?, c'est que votre
code HTML encodé UTF-8 n'est pas correctement interprété.
Sous Firefox, vérifiez si le navigateur a bien basculé l'interprétation des caractères spéciaux en UTF-8:
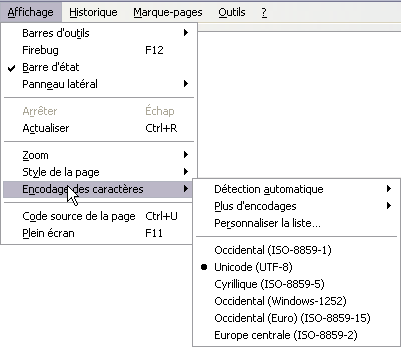
Si ce n'est pas Unicode qui est coché, c'est que le navigateur n'a pas pris en compte
les instructions de la balise META.
Si c'est unicode qui est coché, c'est que le code source n'est pas correctement encodé.
Dans tous les autres cas, les caractères accentués doivent s'afficher correctement. Entraînez-vous avec des portions de texte en russe ou dans d'autres langues pour bien vérifier le bon encodage UTF-8
L'hybridation des pages encodées ISOxx ou UTF-8 est fortement déconseillée. Toute la chaîne logicielle doit être homogène. C'est ce que l'on abordera dans le sujet suivant:
encoder la base de données en UTF8
Tous les articles sur ce thème